Unicode

Awesome Unicode  ¶
¶
> 令人愉快的 Unicode 花絮、包和资源的精选列表.
请阅读 contribution guidelines 在贡献之前. 关键的 Unicode 术语在 glossary.
交叉张贴到 Wisdom's Dev Blog
Foreword¶
Unicode 很棒! 在 Unicode 出现之前,国际通信非常费力——每个人都在 ASCII 的上半部分定义了他们单独的扩展字符集(称为代码页),这会发生冲突——想想看,讲德语的人与讲韩语的人协调使用哪个 127 个字符的代码页. 值得庆幸的是,Unicode 标准流行起来并统一通信. Unicode 8.0 标准化了来自超过 129 个文字的超过 120,000 个字符 - 一些是现代的,一些是古代的,还有一些仍未破译. Unicode 处理从左到右和从右到左的文本,组合标记,并包括不同的文化、政治、宗教字符和表情符号. Unicode 非常人性化——但最终却被低估了.
Quick Unicode Background¶
What Characters Does the Unicode Standard Include?¶
Unicode 标准定义了当今所有主要语言中使用的字符代码. 文字包括欧洲字母文字、中东从右到左的文字和许多亚洲文字.
Unicode 标准还包括标点符号、变音符号、数学符号、技术符号、箭头、装饰符号、表情符号等.它为变音符号提供了代码,这些变音符号修饰字符标记,例如波浪号 (~),与 base 结合使用表示重音字母的字符(例如ñ). 总之,Unicode 标准 9.0 版提供了来自世界字母表、表意文字集和符号集合的 128,172 个字符的代码.
大多数常用字符适合前 64K 个代码点,代码空间的一个区域称为基本多语言平面,简称 BMP. 还有 16 个其他补充平面可用于编码其他字符,目前有超过 850,000 个未使用的代码点. 正在考虑将更多字符添加到标准的未来版本中.
Unicode 标准还保留代码点供私人使用. 供应商或最终用户可以在内部为他们自己的字符和符号分配这些,或者将它们与专门的字体一起使用. BMP 上有 6,400 个私人使用代码点和另外 131,068 个补充私人使用代码点,如果 6,400 个不足以满足特定应用.
Unicode Character Encodings¶
字符编码标准不仅定义了每个字符的标识及其数值或代码点,还定义了该值如何以位表示.
Unicode 标准定义了三种编码形式,允许以字节、字或双字为导向的格式(即每个代码单元 8、16 或 32 位)传输相同的数据. 所有三种编码形式都对相同的通用字符库进行编码,并且可以在不丢失数据的情况下有效地相互转换. Unicode 联盟完全认可使用这些编码形式中的任何一种作为实现 Unicode 标准的一致方式.
UTF-8 在 HTML 和类似协议中很流行. UTF-8 是一种将所有 Unicode 字符转换为可变长度字节编码的方法. 它的优点是与熟悉的 ASCII 集对应的 Unicode 字符具有与 ASCII 相同的字节值,并且 Unicode 字符转换为 UTF-8 可以与许多现有软件一起使用,而无需大量的软件重写.
UTF-16 在许多需要平衡有效访问字符和经济使用存储的环境中很流行. 它相当紧凑,所有频繁使用的字符都适合一个 16 位代码单元,而所有其他字符都可以通过成对的 16 位代码单元访问.
UTF-32 在不关心内存空间但需要固定宽度、单个代码单元访问字符的情况下很有用. 使用 UTF-32 时,每个 Unicode 字符都编码在一个 32 位代码单元中.
所有三种编码形式的每个字符最多需要 4 个字节(或 32 位)的数据.
Lets talk Numbers¶
The Unicode characterset is divided into 17 core segments called "planes", which are further divided into blocks. Each plane has space for 65,536 (2¹⁶) codepoints, supporting a grand total of 1,114,112 codepoints. There are two "Private Use Area" planes (#16 & #17) that are allocated to be used however one wishes. These two Private Use planes account for 131,072 codepoints.
| # | Name | Range |
|---|---|---|
| 1. | 基本多语言平面 | (U+0000 到 U+FFFF) |
| 2. | 补充多语言平面 | (U+10000 到 U+1FFFF) |
| 3. | 补充表意平面 | (U+20000 到 U+2FFFF) |
| 4. | 第三表意平面 | (U+30000 到 U+3FFFF) |
| 5. | 平面 5(未分配) | (U+40000 到 U+4FFFF) |
| 6. | 平面 6(未分配) | (U+50000 到 U+5FFFF) |
| 7. | 平面 7(未分配) | (U+60000 到 U+6FFFF) |
| 8. | 平面 8(未分配) | (U+70000 到 U+7FFFF) |
| 9. | 平面 9(未分配) | (U+80000 到 U+8FFFF) |
| 10. | 平面 10(未分配) | (U+90000 到 U+9FFFF) |
| 11. | 平面 11(未分配) | (U+A0000 到 U+AFFFF) |
| 12. | 平面 12(未分配) | (U+B0000 到 U+BFFFF) |
| 13. | 平面 13(未分配) | (U+C0000 到 U+CFFFF) |
| 14. | 平面 14(未分配) | (U+D0000 到 U+DFFFF) |
| 15. | 增补专机 | (U+E0000 到 U+EFFFF) |
| 16. | 补充私人使用区 - A | (U+F0000 到 U+FFFFF) |
| 17. | 补充私人使用区 - B | (U+100000 到 U+10FFFF) |
第一个平面称为基本多语言平面或 BMP. 它包含从 U+0000 到 U+FFFF 的代码点,这些是最常用的字符. 其他十六个位面 (U+010000 → U+10FFFF) 称为补充位面或星体位面.
UTF-16 Surrogate Pairs¶
> BMP 之外的字符,例如 U+1D306 tetragram for center (),只能使用两个 16 位代码单元以 UTF-16 编码:0xD834 0xDF06. 这称为代理对. 请注意,代理对仅表示单个字符. 代理对的第一个代码单元始终在 0xD800 到 0xDBFF 的范围内,称为高代理或前导代理. 代理对的第二个代码单元总是在 0xDC00 到 0xDFFF 的范围内,称为低代理或尾代理.
> 代理对:单个抽象字符的表示,由 两个 16 位代码单元的序列,其中该对的第一个值是高代理项 代码单元,第二个值是低代理代码单元. 代理对仅在 UTF-16 中使用. (参见第 3.9 节,Unicode 编码 形式.) - Unicode 8.0.0 Chapter 3 - Surrogates
Calculating Surrogate Pairs¶
UTF-16 中的Unicode 字符 Pile of Poo (U+1F4A9) 必须编码为代理对,即两个代理. 要将任何代码点转换为代理项对,请使用以下算法(在 JavaScript 中). 请记住,我们使用的是十六进制表示法.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 };
var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
// 反转转换
var Code_Point = function(High_Surrogate, Low_Surrogate){
返回 (High_Surrogate - 0xD800) * 0x400 + Low_Surrogate - 0xDC00 + 0x10000;
};
> var 代码点 = 0x1F4A9; // 0x1F4A9 == 128169
> High_Surrogate(代码点).toString(16)
“d83d” // 0xD83D == 55357
> Low_Surrogate(代码点).toString(16)
“dca9” // 0xDCA9 == 56489
> String.fromCharCode( High_Surrogate(codepoint) , Low_Surrogate(codepoint) );
""
> 字符串.fromCodePoint(0x1F4A9)
""
> '\ud83d\udca9'
""
Composing & Decomposing¶
Unicode 包括一种修改字符形状的机制,它极大地扩展了支持的字形库. 这涵盖了组合变音标记的使用. 它们被插入到主角之后. 多个组合变音符号可以叠加在同一个字符上. Unicode 还包含大多数正常使用的字母/变音符号组合的预组合版本.
某些字符序列也可以表示为单个字符,称为预组合字符(或复合字符或可分解字符). 例如,字符“ü”可以编码为单个代码点 U+00FC“ü”或基本字符 U+0075“u”后跟非空格字符 U+0308“¨”. Unicode 标准对预组合字符进行编码以与已建立的标准(例如 Latin 1)兼容,其中包括许多预组合字符,例如“ü”和“ñ”.
为了一致性或分析,可以分解预组合字符. 例如,在按字母顺序排列(整理)名称列表时,字符“ü”可能会分解为“u”后跟非空格字符“¨”. 字符分解后,归类可能更容易处理字符,因为它可以作为“u”进行修改处理. 这使得字符修饰符不影响字母顺序的语言更容易按字母顺序排序. Unicode 标准定义了 decompositions 对于所有预组合字符. 它还定义了规范化形式以提供字符的唯一表示.
Myths of Unicode¶
来自马克·戴维斯 Unicode Myths 幻灯片. - Unicode is simply a 16-bit code - Some people are under the misconception that Unicode is simply a 16-bit code where each character takes 16 bits and therefore there are 65,536 possible characters. This is not, actually, correct. It is the single most common myth about Unicode, so if you thought that, don't feel bad.
-
您可以使用任何未分配的代码点供内部使用 - 不.最终那个洞将被不同的字符填充. 而是使用私人使用或非字符.
-
每个 Unicode 代码点代表一个字符 - 不,有很多非字符(FFFE、FFFF、1FFFE,……) 还有代理代码点、私有和未分配的代码点以及控制/格式“字符”(RLM、ZWNJ 等)
-
Unicode 将用完空间 - 如果它是线性的,我们将在公元 2140 年用完. 但它不是线性的. 请参阅 http://www.unicode.org/roadmaps/
-
大小写映射为 1-1 - 不.它们也可以是:
- 一对多:(ß → SS )
- 上下文:(…Σ ↔ …σ AND …Σ… ↔ …σ… )
- 语言环境敏感:( I ↔ ı 和 İ ↔ i )
Applied Unicode Encodings¶
| 编码类型 | 原始编码 |
|---|---|
| HTML Entity (Decimal) | 🖖 |
| HTML Entity (Hexadecimal) | 🖖 |
| 网址转义码 | %F0%9F%96%96 |
| UTF-8(十六进制) | 0xF0 0x9F 0x96 0x96 (f09f9696) |
| UTF-8(二进制) | 11110000:10011111:10010110:10010110 |
| UTF-16/UTF-16BE(十六进制) | 0xD83D 0xDD96 (d83ddd96) |
| UTF-16LE(十六进制) | 0x3DD8 0x96DD (3dd896dd) |
| UTF-32/UTF-32BE(十六进制) | 0x0001F596 (0001f596) |
| UTF-32LE(十六进制) | 0x96F50100 (96f50100) |
| 八进制转义序列 | \360\237\226\226 |
Source Code¶
| 编码类型 | 原始编码 |
|---|---|
| JavaScript | \u1F596 |
| JSON | \u1F596 |
| 丙 | \u1F596 |
| C++ | \u1F596 |
| 爪哇 | \u1F596 |
| 蟒蛇 | \u1F596 |
| 佩尔 | \x{1F596} |
| 红宝石 | \u{1F596} |
| CSS | \01F596 |
Awesome Characters List¶
Special Characters¶
Unicode 联盟发布了一个 general punctuation chart 您可以在哪里找到更多详细信息.
| 字符 | 名称 | 说明 |
|---|---|---|
' ' |
U+FEFF(字节顺序标记 - BOM) | 具有字节重新排序明确的重要特性. 它也是零宽度的,并且是不可见的. 在不兼容的软件(如 PHP 解释器)中,这会导致各种有趣的行为. |
'' |
'\uFFEF' 反转字节顺序标记 (BOM) | 不等同于合法字符,除了文本的开头. |
' ' |
'\u200B' 零宽度不间断空格 | (一个没有外观的字符,除了防止连字的形成之外没有任何作用). |
' ' |
U+00A0 不间断空间 | 强制相邻的字符粘在一起. 在 HTML 中称为 ` . |
| ``` U+00AD 软连字符 | (在 HTML 中:)类似于零宽度空间,但如果(且仅当)发生中断时显示连字符. | |
'' |
U+200D 零宽度连接器 | 强制相邻字符连接在一起(例如,阿拉伯字符或支持的表情符号). 可以用它来组合顺序组合的表情符号. |
'' |
U+2060 字连接器 | 与 U+00A0 相同,但完全不可见. 适合在 Twitter 上写@font-face. |
' ' |
U+1680 OGHAM 空间标记 | 一个看起来像破折号的空间. 伟大的让程序员接近疯狂:1 + 2 === 3. |
';' |
U+037E 希腊问号 | 与分号相似. 这也是惹恼开发人员的一种有趣方式. |
| ``` U+202D | 将文本方向更改为从左到右. | |
| ``` U+202E | 将文本方向更改为从右到左: | |
'ꓸ' |
U+A4F8 傈僳语 LETTER TONE MYA TI | 与古文字相似. |
'ꓹ' |
U+A4F9 LISU LETTER TONE NA PO | 与逗号字符相似. |
'ꓼ' |
U+A4FC LISU LETTER TONE MYA NA | A lookalike for the semi-colon character. |
'ꓽ' |
U+A4FD LISU LETTER TONE MYA JEU | 冒号字符相似. |
'︀' |
变体选择器(U+FE00 到 U+FE0F 和 U+E0100 到 U+E01EF) | 具有 ID_Continue 属性的 256 个零宽度字符块 - 这意味着它们可以用于变量名称(不是第一个字母). 这些特别之处在于鼠标光标在它们组合字符时经过它们 - 与大多数其他零宽度字符不同. |
'ᅟ' |
U+115F 韩文初音填料 | 一般来说,它会产生一个空间. 如果在渲染中未明确支持,则渲染为零宽度(不可见). 指定ID_Start |
'ᅠ' |
U+1160 HANGUL JUNGSEONG 填料 | 也许它产生了一个空间? 如果在渲染中未明确支持,则渲染为零宽度(不可见). 指定ID_Start |
'ㅤ' |
U+3164 韩文填充符 | 一般来说,它会产生一个空间. 如果在渲染中未明确支持,则渲染为零宽度(不可见). 指定ID_Start |
| #### Wait a second... what did I just read? |
Variable identifiers can effectively include whitespace!¶
U+3164 HANGUL FILLER 字符显示为前进空白字符. 字符呈现为完全不可见(并且不前进,即“零宽度”),如果没有明确 supported in rendering . 这意味着不应该显示丑陋的字符替换 (�) 符号.
我还不确定为什么 U+3164 被指定为这种行为. 有趣的是,U+3164 是在 1.1 版(1993 年)中添加到 Unicode 中的——所以联盟一定有很多时间来考虑它. 无论如何,这里有几个例子.
> var ᅟ = 'foo';
undefined
>ᅟ
'foo'
> 是 ᅠ= 警报;
undefined
> var foo = '酒吧'
undefined
> if ( foo ===`baz` ){} // 警报
undefined
> var varᅠfooᅠ\u{A60C}ᅠπ = 'bar';
undefined
> var ᅠ foo ꘌ ᅠ π
'bar'
注意:我已经在 Ubuntu 和 OS X 上使用以下测试了 U+3164 渲染:
node、php、ruby、python3.5、scala、vim、cat、chrome+github gist. Atom 是唯一一个因(错误地)显示空框而失败的系统. 我还没有在 Emacs 和 Sublime 上测试它. 据我了解,Unicode 联盟不会重新分配或重命名字符或代码点,但可能会被说服更改 ID_Start/ID_Continue 等字符属性.
Modifiers¶
零宽度连接符 (ZWJ) 是一种非印刷字符,用于某些复杂文字(例如阿拉伯文字或任何印度文字)的计算机排版. 当放置在两个原本不会连接的字符之间时,ZWJ 会使它们以连接的形式打印.
零宽度非连接符 (ZWNJ) 是一种非打印字符,用于使用连字的书写系统的计算机化. 当放置在两个原本会连接成连字的字符之间时,ZWNJ 会导致它们分别以最终形式和初始形式打印. 这也是空格字符的效果,但是当希望将单词靠得更近或将单词与其词素连接时,会使用 ZWNJ.
> '一个'
“A”
> 'a\u{0308}'
“A”
> 'a\u{20DE}\u{0308}'
“a⃞̈”
> 'a\u{20DE}\u{0308}\u{20DD}'
“a⃞̈⃝”
// 修改不可见字符
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{ 200E}'
""
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{ 200E}'.长度
10
:collision: Uppercase Transformation Collisions¶
| 字符 | 代码点 | 输出字符 |
|---|---|---|
| ß | 0x00DF | SS |
| 我 | 0x0131 | 我 |
| ſ | 0x017F | S |
| fi | 0xFB00 | FF |
| 网络 | 0xFB01 | FI |
| 0xFB02 | ``在'' | |
| ffi | 0xFB03 | ``费用'' |
| ffl | 0xFB04 | FFL |
| ſt | 0xFB05 | ST |
| st | 0xFB06 | ST |
:collision: Lowercase Transformation Collisions¶
| 字符 | 代码点 | 输出字符 |
|---|---|---|
| K | 0x212A | k |
Quirks and Troubleshooting¶
-
字符串长度通常由计算代码点来确定.这意味着代理项对将计为两个字符. 组合多个变音符号可以叠加在同一个字符上.
a + ̈ == ̈a,增加长度,同时只产生一个字符. -
同样,反转字符串通常是一项非常重要的任务.同样,代理对和变音符号必须一起反转. ES Reverser provides a pretty good solution.
-
大写和小写映射并不总是一对一的.它们也可以是:
- 一对多:(ß → SS )
- 上下文:(…Σ ↔ …σ AND …Σ… ↔ …σ… )
- 语言环境敏感:( I ↔ ı 和 İ ↔ i )
One-To-Many Case Mappings¶
以下大多数字符在大写时表示它们的一对多大小写映射,而其他字符应小写. 这个列表应该分开
| 代码点 | 人物 | 名称 | 映射字符 | 映射代码点 |
|---|---|---|---|---|
| U+00DF | ß |
拉丁文小写字母升号 S | s, s |
U+0073, U+0073 |
| U+0130 | İ |
带点的拉丁文大写字母 I | i, ̇ |
U+0069, U+0307 |
| U+0149 | ʼn |
带撇号的拉丁文小写字母 N | ``,n` |
U+02BC, U+006E |
| U+01F0 | ǰ |
带 CARON 的拉丁文小写字母 J | j, ̌ |
U+006A, U+030C |
| U+0390 | α |
带有 DIALYTIKA 和 TONOS 的希腊小写字母 IOTA | ι, ̈, ́ |
U+03B9、U+0308、U+0301 |
| U+03B0 | ð |
带有 DIALYTIKA 和 TONOS 的希腊小写字母 UPSILON | υ, ̈, ́ |
U+03C5、U+0308、U+0301 |
| U+0587 | : 和亚美尼亚小连字 ECH YIWN | : e'',u'' |
U+0565, U+0582 | : |
| U+1E96 | ẖ |
带下划线的拉丁文小写字母 H | h, ̱ |
U+0068, U+0331 |
| U+1E97 | ẗ |
带分音符的拉丁文小写字母 T | t, ̈ |
U+0074, U+0308 |
| U+1E98 | ẘ |
带圆环的拉丁文小写字母 W | w, ̊ |
U+0077、U+030A |
| U+1E99 | ẙ |
带上环的拉丁文小写字母 Y | y, ̊ |
U+0079, U+030A |
| U+1E9A | ẚ |
带右半环的拉丁文小写字母 A | a, ʾ |
U+0061, U+02BE |
| U+1E9E | ẞ |
拉丁文大写字母 SHARP S | s, s |
U+0073, U+0073 |
| U+1F50 | ὐ |
带有 PSILI 的希腊小写字母 UPSILON | υ, ̓ |
U+03C5, U+0313 |
| U+1F52 | ὒ |
带 PSILI 和 VARIA 的希腊小写字母 UPSILON | υ, ̓, ̀ |
U+03C5、U+0313、U+0300 |
| U+1F54 | ὔ |
带有 PSILI 和 OXIA 的希腊小写字母 UPSILON | υ, ̓, ́ |
U+03C5、U+0313、U+0301 |
| U+1F56 | ὖ |
带有 PSILI 和 PERISPOMENI 的希腊小写字母 UPSILON | υ, ̓, ͂ |
U+03C5、U+0313、U+0342 |
| U+1F80 | ᾀ |
带 PSILI 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἀ, i |
U+1F00, U+03B9 |
| U+1F81 | ᾁ |
带 DASIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἁ, i |
U+1F01, U+03B9 |
| U+1F82 | ᾂ |
带 PSILI、VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἂ, ι |
U+1F02, U+03B9 |
| U+1F83 | ᾃ |
带 DASIA 和 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἃ, ι |
U+1F03, U+03B9 |
| U+1F84 | ᾄ |
带 PSILI、OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | 是,ι |
U+1F04, U+03B9 |
| U+1F85 | ᾅ |
带 DASIA 和 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἅ, ι |
U+1F05, U+03B9 |
| U+1F86 | ᾆ |
带 PSILI 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἆ, ι |
U+1F06, U+03B9 |
| U+1F87 | ᾇ |
带 DASIA 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ἇ, ι |
U+1F07, U+03B9 |
| U+1F88 | ᾈ |
带有 PSILI 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἀ, i |
U+1F00, U+03B9 |
| U+1F89 | ᾉ |
带 DASIA 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἁ, i |
U+1F01, U+03B9 |
| U+1F8A | ᾊ |
带有 PSILI 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἂ, ι |
U+1F02, U+03B9 |
| U+1F8B | ᾋ |
带 DASIA 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἃ, ι |
U+1F03, U+03B9 |
| U+1F8C | ᾌ |
带有 PSILI 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | 是,ι |
U+1F04, U+03B9 |
| U+1F8D | ᾍ |
带有 DASIA 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἅ, ι |
U+1F05, U+03B9 |
| U+1F8E | ᾎ |
GREEK CAPITAL LETTER ALPHA WITH PSILI AND PERISPOMENI AND PROSGEGRAMMENI | ἆ, ι |
U+1F06, U+03B9 |
| U+1F8F | ᾏ |
带 DASIA 和 PERISPOMENI 和 PROSGEGRAMMENI 的希腊大写字母 ALPHA | ἇ, ι |
U+1F07, U+03B9 |
| U+1F90 | ᾐ |
带 PSILI 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἠ, i |
U+1F20, U+03B9 |
| U+1F91 | ᾑ |
带有 DASIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἡ, i |
U+1F21, U+03B9 |
| U+1F92 | ᾒ |
带 PSILI、VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἢ, i |
U+1F22, U+03B9 |
| U+1F93 | ᾓ |
带 DASIA 和 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἣ, i |
U+1F23, U+03B9 |
| U+1F94 | ᾔ |
带 PSILI、OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἤ, i |
U+1F24, U+03B9 |
| U+1F95 | ᾕ |
带 DASIA 和 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἥ, i |
U+1F25, U+03B9 |
| U+1F96 | ᾖ |
带 PSILI 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἦ',i' |
U+1F26, U+03B9 |
| U+1F97 | ᾗ |
带有 DASIA 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ἧ, i |
U+1F27, U+03B9 |
| U+1F98 | ᾘ |
带有 PSILI 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἠ, i |
U+1F20, U+03B9 |
| U+1F99 | ᾙ |
带 DASIA 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἡ, i |
U+1F21, U+03B9 |
| U+1F9A | ᾚ |
带有 PSILI 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἢ, i |
U+1F22, U+03B9 |
| U+1F9B | ᾛ |
带 DASIA 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἣ, i |
U+1F23, U+03B9 |
| U+1F9C | ᾜ |
带 PSILI 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἤ, i |
U+1F24, U+03B9 |
| U+1F9D | ᾝ |
带有 DASIA 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἥ, i |
U+1F25, U+03B9 |
| U+1F9E | ᾞ |
带 PSILI 和 PERISPOMENI 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἦ',i' |
U+1F26, U+03B9 |
| U+1F9F | ᾟ |
带 DASIA 和 PERISPOMENI 和 PROSGEGRAMMENI 的希腊大写字母 ETA | ἧ, i |
U+1F27, U+03B9 |
| U+1FA0 | ᾠ |
带 PSILI 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὠ, ι |
U+1F60, U+03B9 |
| U+1FA1 | ᾡ |
带 DASIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | c',i' |
U+1F61, U+03B9 |
| U+1FA2 | ᾢ |
带 PSILI 和 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὢ, ι |
U+1F62, U+03B9 |
| U+1FA3 | ᾣ |
带 DASIA 和 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὣ, ι |
U+1F63, U+03B9 |
| U+1FA4 | ᾤ |
带 PSILI、OXIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὤ, ι |
U+1F64, U+03B9 |
| U+1FA5 | ᾥ |
带 DASIA 和 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὥ, ι |
U+1F65, U+03B9 |
| U+1FA6 | ᾦ |
带 PSILI 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὦ, ι |
U+1F66, U+03B9 |
| U+1FA7 | ᾧ |
带 DASIA 和 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὧ, i |
U+1F67, U+03B9 |
| U+1FA8 | ᾨ |
带 PSILI 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὠ, ι |
U+1F60, U+03B9 |
| U+1FA9 | ᾩ |
带有 DASIA 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὡ, ι |
U+1F61, U+03B9 |
| U+1FAA | ᾪ |
带 PSILI 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὢ, ι |
U+1F62, U+03B9 |
| U+1FAB | ᾫ |
带 DASIA 和 VARIA 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὣ, ι |
U+1F63, U+03B9 |
| U+1FAC | ᾬ |
带 PSILI 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὤ, i |
U+1F64, U+03B9 |
| U+1FAD | ᾭ |
带 DASIA 和 OXIA 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὥ, ι |
U+1F65, U+03B9 |
| U+1FAE | ᾮ |
带 PSILI 和 PERISPOMENI 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὦ, ι |
U+1F66, U+03B9 |
| U+1FAF | ᾯ |
带 DASIA 和 PERISPOMENI 和 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ὧ, i |
U+1F67, U+03B9 |
| U+1FB2 | ᾲ |
带有 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | ὰ, i |
U+1F70, U+03B9 |
| U+1FB3 | ᾳ |
带 YPOGEGRAMMENI 的希腊小写字母 ALPHA | a',i' |
U+03B1, U+03B9 |
| U+1FB4 | ᾴ |
带 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | a',i' |
U+03AC, U+03B9 |
| U+1FB6 | ᾶ |
带 PERISPOMENI 的希腊小写字母 ALPHA | a,͂ |
U+03B1、U+0342 |
| U+1FB7 | ᾷ |
带 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ALPHA | a,͂,i |
U+03B1、U+0342、U+03B9 |
| U+1FBC | ᾼ |
带有 PROSGEGRAMMENI 的希腊大写字母 ALPHA | a',i' |
U+03B1, U+03B9 |
| U+1FC2 | ῂ |
带有 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | ὴ, i |
U+1F74, U+03B9 |
| U+1FC3 | ῃ |
带 YPOGEGRAMMENI 的希腊小写字母 ETA | h',i' |
U+03B7, U+03B9 |
| U+1FC4 | ῄ |
带 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 ETA | 或',我' |
U+03AE, U+03B9 |
| U+1FC6 | ῆ |
带 PERISPOMENI 的希腊小写字母 ETA | η, ͂ |
U+03B7, U+0342 |
| U+1FC7 | ῇ |
带 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 ETA | h, ͂,i` |
U+03B7、U+0342、U+03B9 |
| U+1FCC | ῌ |
带有 PROSGEGRAMMENI 的希腊大写字母 ETA | h',i' |
U+03B7, U+03B9 |
| U+1FD2 | ῒ |
带有 DIALYTIKA 和 VARIA 的希腊小写字母 IOTA | ι, ̈, ̀ |
U+03B9、U+0308、U+0300 |
| U+1FD3 | 我 |
带有 DIALYTIKA 和 OXIA 的希腊小写字母 IOTA | i, ̈, ́ |
U+03B9、U+0308、U+0301 |
| U+1FD6 | ῖ |
带 PERISPOMENI 的希腊小写字母 IOTA | i, ͂ |
U+03B9,U+0342 |
| U+1FD7 | ῗ |
带有 DIALYTIKA 和 PERISPOMENI 的希腊小写字母 IOTA | ι, ̈, ͂ |
U+03B9、U+0308、U+0342 |
| U+1FE2 | ῢ |
带有 DIALYTIKA 和 VARIA 的希腊小写字母 UPSILON | υ, ̈, ̀ |
U+03C5、U+0308、U+0300 |
| U+1FE3 | ‘冰’ | 带 DIALYTIKA 和 OXIA 的希腊小写字母 UPSILON | y, ̈, ́ |
U+03C5、U+0308、U+0301 |
| U+1FE4 | ῤ |
带有 PSILI 的希腊小写字母 RHO | ρ, ̓ |
U+03C1, U+0313 |
| U+1FE6 | ῦ |
带 PERISPOMENI 的希腊小写字母 UPSILON | υ, ͂ |
U+03C5、U+0342 |
| U+1FE7 | ῧ |
带有 DIALYTIKA 和 PERISPOMENI 的希腊小写字母 UPSILON | υ, ̈, ͂ |
U+03C5、U+0308、U+0342 |
| U+1FF2 | ῲ |
带有 VARIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ὼ, i |
U+1F7C, U+03B9 |
| U+1FF3 | ῳ |
带 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ‘哦’,‘我’ | U+03C9, U+03B9 |
| U+1FF4 | ῴ |
带 OXIA 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ώ, ι |
U+03CE, U+03B9 |
| U+1FF6 | ῶ |
带 PERISPOMENI 的希腊小写字母 OMEGA | ω, ͂ |
U+03C9, U+0342 |
| U+1FF7 | ῷ |
带 PERISPOMENI 和 YPOGEGRAMMENI 的希腊小写字母 OMEGA | ω, ͂,i` |
U+03C9、U+0342、U+03B9 |
| U+1FFC | ῼ |
带有 PROSGEGRAMMENI 的希腊大写字母 OMEGA | ‘哦’,‘我’ | U+03C9, U+03B9 |
| U+FB00 | `` | 拉丁文小号连字 FF | f, f |
U+0066, U+0066 |
| U+FB01 | fi |
拉丁小连字 FI | f, i |
U+0066, U+0069 |
| U+FB02 | fl |
拉丁小连字 FL | f, l |
U+0066、U+006C |
| U+FB03 | ffi |
拉丁文小写连字 FFI | f, f, i |
U+0066、U+0066、U+0069 |
| U+FB04 | ffl |
拉丁小连字 FFL | f, f, l |
U+0066、U+0066、U+006C |
| U+FB05 | ſt |
拉丁文小号连字长 ST | s, t |
U+0073, U+0074 |
| U+FB06 | st |
拉丁小连字 ST | s, t |
U+0073, U+0074 |
| U+FB13 | : | : 亚美尼亚小连字男士现在 | : m'',n'' |
U+0574, U+0576 |
| U+FB14 | : 我'' | 亚美尼亚小连字男士 ECH |:m'', ``e'' |
U+0574, U+0565 | : | |
| U+FB15 | : 米'' |: 亚美尼亚小连字男士 INI |:m'', ``i'' |
U+0574, U+056B | : | |
| U+FB16 | : ﬖ |
: 亚美尼亚小连字现在查看 | : v'',n'' |
: U+057E, U+0576 |
| U+FB17 | : ﬗ |
: 亚美尼亚小连字男 XEH | : m'',kh'' |
: U+0574, U+056D |
Awesome Packages & Libraries¶
- PhantomScript -

 不可见的 JavaScript 代码执行和社会工程
不可见的 JavaScript 代码执行和社会工程 - ESReverser - 用 JavaScript 编写的可识别 Unicode 的字符串反向器.
- mimic - [滥用]使用 Unicode 制造悲剧
- python-ftfy - 给定 Unicode 文本,使其表示一致并且可能更少损坏.
- vim-troll-stopper - 阻止 Unicode trolls 弄乱您的代码.
Emojis¶
- Unicode Consortium's Emoji Chart
- Emojipedia - Information about specific emoji, news blog.
- emojitracker - 在 Twitter 上使用实时表情符号.
- World Translation Foundation - 一种推广、探索书面文字并将其翻译成表情符号图形字母表的方法.
- Can I Emoji? - 显示 iOS、Android 和 Windows 原生表情符号支持的当前状态.
- How to register an emoji URL
Diversity¶
Unicode 联盟做出了巨大努力,以更好地反映和融合人类多样性,包括文化习俗. 这是财团 diversity report.
同性家庭、牵手、接吻等混合性别表情现已上线. 真正的踢球者是 Emoji combined sequences . 基本上:
| 代码点 | 食谱 | 合并 |
|---|---|---|
| U+1F469 U+200D U+2764 U+FE0F U+200D U+1F469 | ||
| U+1F468 U+200D U+1F468 U+200D U+1F467 U+200D U+1F466 |
此外,表情符号现在支持肤色修饰符.
> 在 Unicode 版本 8.0(2015 年年中)中发布了五个符号修饰字符,为人类表情符号提供一系列肤色. 这些字符基于 Fitzpatrick 量表的六种音调,这是皮肤病学公认的标准(网上有很多这种量表的示例,例如 FitzpatrickSkinType.pdf). 确切的阴影可能因实现而异. -- Unicode Consortium's Diversity report
| 代码 | 名称 | 样品 |
|---|---|---|
| U+1F3FB | 表情符号修饰符 FITZPATRICK TYPE-1-2 | |
| U+1F3FC | 表情符号修饰符 FITZPATRICK TYPE-3 | |
| U+1F3FD | 表情符号修改器 FITZPATRICK TYPE-4 | |
| U+1F3FE | 表情符号修改器 FITZPATRICK TYPE-5 | |
| U+1F3FF | 表情符号修饰符 FITZPATRICK TYPE-6 |
只需使用一种肤色修饰符“\u{1F466}\u{1F3FE}”跟随所需的表情符号.
![]() +
+
![]() →
→
![]()
![]()
Creatively Naming Variables and Methods¶
示例是用 JavaScript (ES6) 编写的
一般来说,字符指定 ID_START property 可以用在变量名的开头. 指定的字符 ID_CONTINUE 属性可以用在变量的第一个字符之后.
功能兰德(米,小号){ ... };
String.prototype.reverseⵑ = function(){..};
Number.prototype.isTrueɁ = function(){..};
其中 WhatDoesThisDoɁɁɁɁ = 42
这里有一些非常有创意的变量名来自 Mathias Bynes
// 多么方便!
var π = Math.PI;
// 有时,您只需要使用 JavaScript 的错误部分:
varಠ_ಠ=评估;
// 代码,你没有工作?!
var l_ಠ益ಠ_l = 42;
// 用于函数式编程的 JavaScript 库怎么样?
var λ = function() {};
// 混淆枯燥的变量名以获得伟大的正义
var \u006C\u006F\u006C\u0077\u0061\u0074 = '嘿';
// …或者只是随机组成
是Ꙭלↈⴱ = '嗯';
// 虽然完全有效,但在大多数浏览器中不起作用:
var foo\u200Cbar = 42;
// 这*不是*按位左移 (`<<`):
var 〱〱 = 2;
// 不过,这是:
〱〱 << 〱〱; // 8
// 给自己一个折扣:
var price_9̶9̶_89 = '便宜';
// 有趣的罗马数字
Ⅳ = 4;
Ⅴ = 5;
Ⅳ + Ⅴ; // 9
//克苏鲁在这里
var hͫ̆̒̐ͣ̊̄ͯ͗͏̵̗̻̰̠̬͝ͅe̴̷̬͎̱̘͇͍̾ͦ͊͒͊̓̓̐_̫̠̱̩̭̤͈̑̎̋ͮͩ̒͑̾͋͘ç̳͕̯̭̱̲̣̠̜͋̍o̴̦̗̯̹̼ͭ̐ͨ̊̈͘͠m̶̝̠̭̭̤̻͓͑̓̊ͣͤ̎͟͠e̢̞̮̹͍̞̳̣ͣͪ͐̈t̡̯̳̭̜̠͕͌̈́̽̿ͤ̿̅̑ẖ̱̺̰̳̹̘̰̈́̏ͪ̂̽͂̀͠ ='zalgo';
这是一些 Unicode CSS Classes 来自大卫·沃尔什
<!-- place this within the document head -->
<meta charset="UTF-8" />
<!-- error message -->
<div class="ಠ_ಠ">您无权访问此页面.</div>
<!-- success message -->
<div class="❤">您的更改已成功保存!</div>
.ठ_ठ{
border: 1px solid #f00;
}
.❤ {
背景:浅绿色;
}
Recursive HTML Tag Renaming Script¶
如果您想将所有 HTML 标签重命名为什么都没有,下面的脚本正是您要找的.
但请注意,HTML 不支持所有 unicode 字符.
// U+1160 HANGUL JUNGSEONG FILLER
transformAllTags('ᅠ');
// 一个实际的 HTML 元素节点,看起来像一个注释节点,使用 U+01C3 拉丁字母 RETROFLEX CLICK
// <ǃ-- name="viewport" content="width=device-width"></ǃ-->
transformAllTags('ǃ--');
// 甚至 <ᅠ⃝
transformAllTags('\u{1160}\u{20dd}');
// 作为奖励,所有现有的标签名称都将包含每个字符. h⃞t⃞m⃞l⃞
transformAllTags();
函数 transformAllTags (newName){
// querySelectorAll 实际上并不返回一个数组.
Array.from(document.querySelectorAll('*'))
.forEach(函数(x){
转换标签(x,新名称);
});
}
功能不稳定(str){
返回 str.split('').join('\u{20de}') + '\u{20de}';
}
函数 transformTag(tagIdOrElem, tagType){
var elem = (tagIdOrElem instanceof HTMLElement) ? tagIdOrElem : document.getElementById(tagIdOrElem);
如果(!elem || !(elem instanceof HTMLElement))返回;
var children = elem.childNodes;
var parent = elem.parentNode;
var newNode = document.createElement(tagType||wonky(elem.tagName));
对于(var a=0;a
newNode.setAttribute(elem.attributes[a].nodeName, elem.attributes[a].value);
}
对于 (var i= 0,clen=children.length;i
newNode.appendChild(children[0]); //0...总是指向第一个未移动的元素
}
newNode.style.cssText = elem.style.cssText;
parent.replaceChild(newNode,elem);
}
功能测试开始(海峡){
尝试{
eval(`document.createElement('${str}');`)
返回真;
}
抓住(e){ 返回假; }
}
功能测试继续(海峡){
尝试{
eval(`document.createElement('a${str}');`)
返回真;
}
抓住(e){ 返回假; }
}
这是一些基本结果
// 测试破折号是否可以开始一个 HTML 标签
> 正文开始('-')
< false
> 测试继续('-')
< true
> testBegin('ᅠ-') // 使用 U+1160 HANGUL JUNGSEONG FILLER 前置破折号
< true
Unicode Fonts¶
单一的 TrueType / OpenType 字体格式无法涵盖所有 UTF-8 字符,因为字体中存在 65535 个字形的硬性限制. 由于有超过 110 万个 UTF-8 字形,您需要使用一个字体系列来覆盖它们. - https://en.wikipedia.org/wiki/Unicode_font#List_of_Unicode_fonts - http://www.unifont.org/fontguide/
More Reading¶
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets - 乔尔·斯波尔斯基
- What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
- The Unicode Consortium's Recommended Reading List
- Space Yourself - Smashing Magazine 的间距指南
- JavaScript has a Unicode Problem
- Creative usernames and Spotify account hijacking
Exploring Deeper into Unicode Yourself¶
- Shapecatcher - 画出你要找的角色.
- Confusable Unicode Characters
- Unicode Character Database
- Database Dumps of Codepoints.net
- Unicode Blocks List
- Unicode Character Code Charts
- Unicode Case Charts
- Unicode Normalization Chart
- Unicode FAQ
Overview Map¶
A map of the Basic Multilingual Plane¶
每个带编号的框代表 256 个代码点.
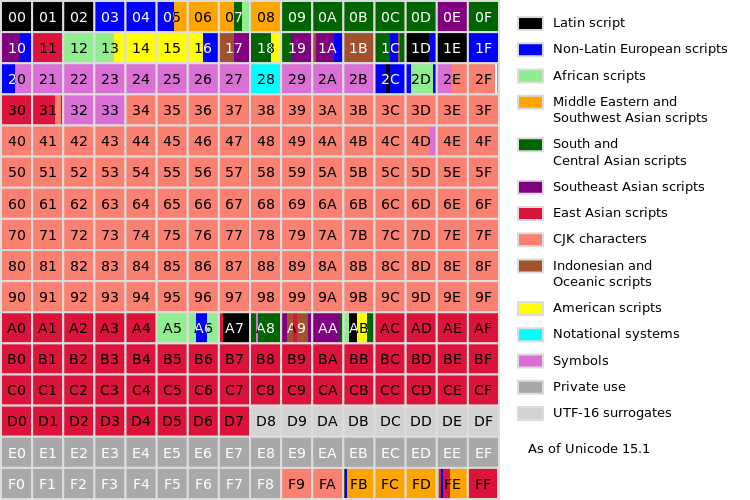
中文、日文和韩文 (CJK) 文字具有共同的背景,统称为 CJK 字符. 在称为汉统一的过程中,通用(共享)字符被识别并命名为“CJK Unified Ideographs”.
Unicode Blocks¶
*Unicode 标准以块的形式将字符组排列在一起. 这是所有 17 个平面的完整块列表. *
| Name | From | To | # Codepoints |
|---|---|---|---|
| Basic Latin | U+0000 | U+007F | (128) |
| Latin-1 Supplement | U+0080 | U+00FF | (128) |
| Latin Extended-A | U+0100 | U+017F | (128) |
| Latin Extended-B | U+0180 | U+024F | (208) |
| IPA Extensions | U+0250 | U+02AF | (96) |
| Spacing Modifier Letters | U+02B0 | U+02FF | (80) |
| Combining Diacritical Marks | U+0300 | U+036F | (112) |
| Greek and Coptic | U+0370 | U+03FF | (135) |
| Cyrillic | U+0400 | U+04FF | (256) |
| Cyrillic Supplement | U+0500 | U+052F | (48) |
| Armenian | U+0530 | U+058F | (89) |
| Hebrew | U+0590 | U+05FF | (87) |
| Arabic | U+0600 | U+06FF | (255) |
| Syriac | U+0700 | U+074F | (77) |
| Arabic Supplement | U+0750 | U+077F | (48) |
| Thaana | U+0780 | U+07BF | (50) |
| NKo | U+07C0 | U+07FF | (59) |
| Samaritan | U+0800 | U+083F | (61) |
| Mandaic | U+0840 | U+085F | (29) |
| Arabic Extended-A | U+08A0 | U+08FF | (50) |
| Devanagari | U+0900 | U+097F | (128) |
| Bengali | U+0980 | U+09FF | (93) |
| Gurmukhi | U+0A00 | U+0A7F | (79) |
| Gujarati | U+0A80 | U+0AFF | (85) |
| Oriya | U+0B00 | U+0B7F | (90) |
| Tamil | U+0B80 | U+0BFF | (72) |
| Telugu | U+0C00 | U+0C7F | (96) |
| Kannada | U+0C80 | U+0CFF | (87) |
| Malayalam | U+0D00 | U+0D7F | (100) |
| Sinhala | U+0D80 | U+0DFF | (90) |
| Thai | U+0E00 | U+0E7F | (87) |
| Lao | U+0E80 | U+0EFF | (67) |
| Tibetan | U+0F00 | U+0FFF | (211) |
| Myanmar | U+1000 | U+109F | (160) |
| Georgian | U+10A0 | U+10FF | (88) |
| Hangul Jamo | U+1100 | U+11FF | (256) |
| Ethiopic | U+1200 | U+137F | (358) |
| Ethiopic Supplement | U+1380 | U+139F | (26) |
| Cherokee | U+13A0 | U+13FF | (92) |
| Unified Canadian Aboriginal Syllabics | U+1400 | U+167F | (640) |
| Ogham | U+1680 | U+169F | (29) |
| Runic | U+16A0 | U+16FF | (89) |
| Tagalog | U+1700 | U+171F | (20) |
| Hanunoo | U+1720 | U+173F | (23) |
| Buhid | U+1740 | U+175F | (20) |
| Tagbanwa | U+1760 | U+177F | (18) |
| Khmer | U+1780 | U+17FF | (114) |
| Mongolian | U+1800 | U+18AF | (156) |
| Unified Canadian Aboriginal Syllabics Extended | U+18B0 | U+18FF | (70) |
| Limbu | U+1900 | U+194F | (68) |
| Tai Le | U+1950 | U+197F | (35) |
| New Tai Lue | U+1980 | U+19DF | (83) |
| Khmer Symbols | U+19E0 | U+19FF | (32) |
| Buginese | U+1A00 | U+1A1F | (30) |
| Tai Tham | U+1A20 | U+1AAF | (127) |
| Combining Diacritical Marks Extended | U+1AB0 | U+1AFF | (15) |
| Balinese | U+1B00 | U+1B7F | (121) |
| Sundanese | U+1B80 | U+1BBF | (64) |
| Batak | U+1BC0 | U+1BFF | (56) |
| Lepcha | U+1C00 | U+1C4F | (74) |
| Ol Chiki | U+1C50 | U+1C7F | (48) |
| Sundanese Supplement | U+1CC0 | U+1CCF | (8) |
| Vedic Extensions | U+1CD0 | U+1CFF | (41) |
| Phonetic Extensions | U+1D00 | U+1D7F | (128) |
| Phonetic Extensions Supplement | U+1D80 | U+1DBF | (64) |
| Combining Diacritical Marks Supplement | U+1DC0 | U+1DFF | (58) |
| Latin Extended Additional | U+1E00 | U+1FF | (256) |
| Greek Extended | U+1F00 | U+1FFF | (233) |
| General Punctuation | U+2000 | U+206F | (111) |
| Superscripts and Subscripts | U+2070 | U+209F | (42) |
| Currency Symbols | U+20A0 | U+20CF | (31) |
| Combining Diacritical Marks for Symbols | U+20D0 | U+20FF | (33) |
| Letterlike Symbols | U+2100 | U+214F | (80) |
| Number Forms | U+2150 | U+218F | (60) |
| Arrows | U+2190 | U+21FF | (112) |
| Mathematical Operators | U+2200 | U+22FF | (256) |
| Miscellaneous Technical | U+2300 | U+23FF | (251) |
| Control Pictures | U+2400 | U+243F | (39) |
| Optical Character Recognition | U+2440 | U+245F | (11) |
| Enclosed Alphanumerics | U+2460 | U+24FF | (160) |
| Box Drawing | U+2500 | U+257F | (128) |
| Block Elements | U+2580 | U+259F | (32) |
| Geometric Shapes | U+25A0 | U+25FF | (96) |
| Miscellaneous Symbols | U+2600 | U+26FF | (256) |
| Dingbats | U+2700 | U+27BF | (192) |
| Miscellaneous Mathematical Symbols-A | U+27C0 | U+27EF | (48) |
| Supplemental Arrows-A | U+27F0 | U+27FF | (16) |
| Braille Patterns | U+2800 | U+28FF | (256) |
| Supplemental Arrows-B | U+2900 | U+297F | (128) |
| Miscellaneous Mathematical Symbols-B | U+2980 | U+29FF | (128) |
| Supplemental Mathematical Operators | U+2A00 | U+2AFF | (256) |
| Miscellaneous Symbols and Arrows | U+2B00 | U+2BFF | (206) |
| Glagolitic | U+2C00 | U+2C5F | (94) |
| Latin Extended-C | U+2C60 | U+2C7F | (32) |
| Coptic | U+2C80 | U+2CFF | (123) |
| Georgian Supplement | U+2D00 | U+2D2F | (40) |
| Tifinagh | U+2D30 | U+2D7F | (59) |
| Ethiopic Extended | U+2D80 | U+2DDF | (79) |
| Cyrillic Extended-A | U+2DE0 | U+2DFF | (32) |
| Supplemental Punctuation | U+2E00 | U+2E7F | (67) |
| CJK Radicals Supplement | U+2E80 | U+2EFF | (115) |
| Kangxi Radicals | U+2F00 | U+2FDF | (214) |
| Ideographic Description Characters | U+2FF0 | U+2FFF | (12) |
| CJK Symbols and Punctuation | U+3000 | U+303F | (64) |
| Hiragana | U+3040 | U+309F | (93) |
| Katakana | U+30A0 | U+30FF | (96) |
| Bopomofo | U+3100 | U+312F | (41) |
| Hangul Compatibility Jamo | U+3130 | U+318F | (94) |
| Kanbun | U+3190 | U+319F | (16) |
| Bopomofo Extended | U+31A0 | U+31BF | (27) |
| CJK Strokes | U+31C0 | U+31EF | (36) |
| Katakana Phonetic Extensions | U+31F0 | U+31FF | (16) |
| Enclosed CJK Letters and Months | U+3200 | U+32FF | (254) |
| CJK Compatibility | U+3300 | U+33FF | (256) |
| CJK Unified Ideographs Extension A | U+3400 | U+4DBF | (6191) |
| Yijing Hexagram Symbols | U+4DC0 | U+4FF | (64) |
| CJK Unified Ideographs | U+4E00 | U+9FF | (20941) |
| Yi Syllables | U+A000 | U+A48F | (1165) |
| Yi Radicals | U+A490 | U+A4CF | (55) |
| Lisu | U+A4D0 | U+A4FF | (48) |
| Vai | U+A500 | U+A63F | (300) |
| Cyrillic Extended-B | U+A640 | U+A69F | (96) |
| Bamum | U+A6A0 | U+A6FF | (88) |
| Modifier Tone Letters | U+A700 | U+A71F | (32) |
| Latin Extended-D | U+A720 | U+A7FF | (159) |
| Syloti Nagri | U+A800 | U+A82F | (44) |
| Common Indic Number Forms | U+A830 | U+A83F | (10) |
| Phags-pa | U+A840 | U+A87F | (56) |
| Saurashtra | U+A880 | U+A8DF | (81) |
| Devanagari Extended | U+A8E0 | U+A8FF | (30) |
| Kayah Li | U+A900 | U+A92F | (48) |
| Rejang | U+A930 | U+A95F | (37) |
| Hangul Jamo Extended-A | U+A960 | U+A97F | (29) |
| Javanese | U+A980 | U+A9DF | (91) |
| Myanmar Extended-B | U+A9E0 | U+A9FF | (31) |
| Cham | U+AA00 | U+AA5F | (83) |
| Myanmar Extended-A | U+AA60 | U+AA7F | (32) |
| Tai Viet | U+AA80 | U+AADF | (72) |
| Meetei Mayek Extensions | U+AAE0 | 你+AAFF | (23) |
| Ethiopic Extended-A | U+AB00 | U+AB2F | (32) |
| Latin Extended-E | U+AB30 | U+AB6F | (54) |
| Cherokee Supplement | U+AB70 | U+ABBF | (80) |
| Meetei Mayek | U+ABC0 | U+ABFF | (56) |
| Hangul Syllables | U+AC00 | U+D7AF | (2) |
| Hangul Jamo Extended-B | U+D7B0 | U+D7FF | (72) |
| High Surrogates | U+D800 | U+DB7F | (2) |
| High Private Use Surrogates | U+DB80 | U+DBFF | (2) |
| Low Surrogates | U+DC00 | U+DFFF | (2) |
| Private Use Area | U+E000 | U+F8FF | (2) |
| CJK Compatibility Ideographs | U+F900 | 优+发 | (472) |
| Alphabetic Presentation Forms | U+FB00 | U+FB4F | (58) |
| Arabic Presentation Forms-A | U+FB50 | U+FDFF | (643) |
| Variation Selectors | U+FE00 | U+FE0F | (16) |
| Vertical Forms | U+FE10 | U+FE1F | (10) |
| Combining Half Marks | U+FE20 | U+FE2F | (16) |
| CJK Compatibility Forms | U+FE30 | U+FE4F | (32) |
| Small Form Variants | U+FE50 | U+FE6F | (26) |
| Arabic Presentation Forms-B | U+FE70 | 你+FEFF | (141) |
| Halfwidth and Fullwidth Forms | U+FF00 | 你+FFEF | (225) |
| Specials | U+FFF0 | 你+FFFF | (7) |
| Linear B Syllabary | U+10000 | U+1007F | (88) |
| Linear B Ideograms | U+10080 | U+100FF | (123) |
| Aegean Numbers | U+10100 | U+1013F | (57) |
| Ancient Greek Numbers | U+10140 | U+1018F | (77) |
| Ancient Symbols | U+10190 | U+101CF | (13) |
| Phaistos Disc | U+101D0 | U+101FF | (46) |
| Lycian | U+10280 | U+1029F | (29) |
| Carian | U+102A0 | U+102DF | (49) |
| Coptic Epact Numbers | U+102E0 | U+102FF | (28) |
| Old Italic | U+10300 | U+1032F | (36) |
| Gothic | U+10330 | U+1034F | (27) |
| Old Permic | U+10350 | U+1037F | (43) |
| Ugaritic | U+10380 | U+1039F | (31) |
| Old Persian | U+103A0 | U+103DF | (50) |
| Deseret | U+10400 | U+1044F | (80) |
| Shavian | U+10450 | U+1047F | (48) |
| Osmanya | U+10480 | U+104AF | (40) |
| Elbasan | U+10500 | U+1052F | (40) |
| Caucasian Albanian | U+10530 | U+1056F | (53) |
| Linear A | U+10600 | U+1077F | (341) |
| Cypriot Syllabary | U+10800 | U+1083F | (55) |
| Imperial Aramaic | U+10840 | U+1085F | (31) |
| Palmyrene | U+10860 | U+1087F | (32) |
| Nabataean | U+10880 | U+108AF | (40) |
| Hatran | U+108E0 | U+108FF | (26) |
| Phoenician | U+10900 | U+1091F | (29) |
| Lydian | U+10920 | U+1093F | (27) |
| Meroitic Hieroglyphs | U+10980 | U+1099F | (32) |
| Meroitic Cursive | U+109A0 | U+109FF | (90) |
| Kharoshthi | U+10A00 | U+10A5F | (65) |
| Old South Arabian | U+10A60 | U+10A7F | (32) |
| Old North Arabian | U+10A80 | U+10A9F | (32) |
| Manichaean | U+10AC0 | U+10AFF | (51) |
| Avestan | U+10B00 | U+10B3F | (61) |
| Inscriptional Parthian | U+10B40 | U+10B5F | (30) |
| Inscriptional Pahlavi | U+10B60 | U+10B7F | (27) |
| Psalter Pahlavi | U+10B80 | U+10BAF | (29) |
| Old Turkic | U+10C00 | U+10C4F | (73) |
| Old Hungarian | U+10C80 | U+10CFF | (108) |
| Rumi Numeral Symbols | U+10E60 | U+10E7F | (31) |
| Brahmi | U+11000 | U+1107F | (109) |
| Kaithi | U+11080 | U+110CF | (66) |
| Sora Sompeng | U+110D0 | U+110FF | (35) |
| Chakma | U+11100 | U+1114F | (67) |
| Mahajani | U+11150 | U+1117F | (39) |
| Sharada | U+11180 | U+111DF | (94) |
| Sinhala Archaic Numbers | U+111E0 | U+111FF | (20) |
| Khojki | U+11200 | U+1124F | (61) |
| Multani | U+11280 | U+112AF | (38) |
| Khudawadi | U+112B0 | U+112FF | (69) |
| Grantha | U+11300 | U+1137F | (85) |
| Tirhuta | U+11480 | U+114DF | (82) |
| Siddham | U+11580 | U+115FF | (92) |
| Modi | U+11600 | U+1165F | (79) |
| Takri | U+11680 | U+116CF | (66) |
| Ahom | U+11700 | U+1173F | (57) |
| Warang Citi | U+118A0 | U+118FF | (84) |
| Pau Cin Hau | U+11AC0 | U+11AFF | (57) |
| Cuneiform | U+12000 | U+123FF | (922) |
| Cuneiform Numbers and Punctuation | U+12400 | U+1247F | (116) |
| Early Dynastic Cuneiform | U+12480 | U+1254F | (196) |
| Egyptian Hieroglyphs | U+13000 | U+1342F | (1071) |
| Anatolian Hieroglyphs | U+14400 | U+1467F | (583) |
| Bamum Supplement | U+16800 | U+16A3F | (569) |
| Mro | U+16A40 | U+16A6F | (43) |
| Bassa Vah | U+16AD0 | U+16AFF | (36) |
| Pahawh Hmong | U+16B00 | U+16B8F | (127) |
| Miao | U+16F00 | U+16F9F | (133) |
| Kana Supplement | U+1B000 | U+1B0FF | (2) |
| Duployan | U+1BC00 | U+1BC9F | (143) |
| Shorthand Format Controls | U+1BCA0 | U+1BCAF | (4) |
| Byzantine Musical Symbols | U+1D000 | U+1D0FF | (246) |
| Musical Symbols | U+1D100 | U+1D1FF | (231) |
| Ancient Greek Musical Notation | U+1D200 | U+1D24F | (70) |
| Tai Xuan Jing Symbols | U+1D300 | U+1D35F | (87) |
| Counting Rod Numerals | U+1D360 | U+1D37F | (18) |
| Mathematical Alphanumeric Symbols | U+1D400 | U+1D7FF | (996) |
| Sutton SignWriting | U+1D800 | U+1DAAF | (672) |
| Mende Kikakui | U+1E800 | U+1E8DF | (213) |
| Arabic Mathematical Alphabetic Symbols | U+1EE00 | U+1EEFF | (143) |
| Mahjong Tiles | U+1F000 | U+1F02F | (44) |
| Domino Tiles | U+1F030 | U+1F09F | (100) |
| Playing Cards | U+1F0A0 | U+1F0FF | (82) |
| Enclosed Alphanumeric Supplement | U+1F100 | U+1F1FF | (173) |
| Enclosed Ideographic Supplement | U+1F200 | U+1F2FF | (57) |
| Miscellaneous Symbols and Pictographs | U+1F300 | U+1F5FF | (766) |
| Emoticons | U+1F600 | U+1F64F | (80) |
| Ornamental Dingbats | U+1F650 | U+1F67F | (48) |
| Transport and Map Symbols | U+1F680 | U+1F6FF | (98) |
| Alchemical Symbols | U+1F700 | U+1F77F | (116) |
| Geometric Shapes Extended | U+1F780 | U+1F7FF | (85) |
| Supplemental Arrows-C | U+1F800 | U+1F8FF | (148) |
| Supplemental Symbols and Pictographs | U+1F900 | U+1F9FF | (15) |
| CJK Unified Ideographs Extension B | U+20000 | U+2A6DF | (42676) |
| CJK Unified Ideographs Extension C | U+2A700 | U+2B73F | (60) |
| CJK Unified Ideographs Extension D | U+2B740 | U+2B81F | (27) |
| CJK Unified Ideographs Extension E | U+2B820 | U+2CEAF | (2) |
| CJK Compatibility Ideographs Supplement | U+2F800 | U+2FA1F | (542) |
| Tags | U+E0000 | U+E007F | (97) |
| Variation Selectors Supplement | U+E0100 | U+E01EF | (240) |
| Supplementary Private Use Area-A | U+F0000 | U + FFFFF | (4) |
| Supplementary Private Use Area-B | U+100000 | U+10FFFF | (4) |
Principles of the Unicode Standard¶
Unicode 标准规定了以下基本原则:
- Universal repertoire - Every writing system ever used shall be respected and represented in the standard
- 逻辑顺序 - 在双向文本中,字符按逻辑顺序存储,而不是表示形式
- 效率 - 文档必须高效且完整.
- 统一 - 如果不同的文化或语言使用相同的字符,则只能包含一次. 这一点是
- Characters, not glyphs - 只对字符而不是字形进行编码. 简而言之,字形是实际的图形
- 动态组合 - 新字符可以由其他已经标准化的字符组成. 例如,字符“Ä”可以由“A”和分音符号(“¨”)组成.
- 语义 - 包含的字符必须明确定义并与其他字符区分开来.
- 稳定性 - 一旦定义的字符将永远不会被删除或重新分配它们的代码点. 在错误的情况下,代码点应被弃用.
- 纯文本 - 标准中的字符是文本,绝不是标记或元字符.
- 可转换性——所有其他使用的编码都应以 Unicode 编码表示.
注:原理说明来自 codepoints.net
Unicode Versions¶
- Version 9.0.0 (最新版本,2016 年 8 月 - 恰好添加了 7,500 个字符)
- Version 8.0.0
- Version 7.0.0
- Version 6.3.0
- Version 6.2.0
- Version 6.1.0
- Version 6.0.0
- Version 5.2.0
- Version 5.1.0
- 版本 5.0.0(不可用)
- Version 4.0.1
- Version 4.0.0
Contributing¶
请参阅 Awesome Unicode contribution guide 有关如何贡献的详细信息.
Code of Conduct¶
见 Code of Conduct 了解详情. 基本上可以归结为: >为了营造一个开放和热情的环境,我们作为 贡献者和维护者承诺参与我们的项目,并且 我们的社区为每个人提供无骚扰的体验,无论年龄、身体如何 体型、残疾、种族、性别认同和表达、经验水平、 国籍、外貌、种族、宗教或性认同和性取向.
License¶

在法律允许的范围内, contributors 已放弃该作品的所有版权和相关或邻接权. 见 license file 了解详情.